Agents¶
Package that contains all available MMLF agents.
- A list of all agents:
Agent ‘Model-based Direct Policy Search‘ from module mbdps_agent implemented in class MBDPS_Agent.
An agent that uses the state-action-reward-successor_state transitions to learn a model of the environment. It performs direct policy search (similar to the direct policy search agent using a black-box optimization algorithm to optimize the parameters of a parameterized policy) in the model in order to optimize a criterion defined by a fitness function. This fitness function can be e.g. the estimated accumulated reward obtained by this policy in the model environment. In order to enforce exploration, the model is wrapped for an RMax-like behavior so that it returns the reward RMax for all states that have not been sufficiently explored. RMax should be an upper bound to the actual achievable return in order to enforce optimism in the face of uncertainty.
Agent ‘Monte-Carlo‘ from module monte_carlo_agent implemented in class MonteCarloAgent.
An agent which uses Monte Carlo policy evaluation to optimize its behavior in a given environment.
Agent ‘Dyna TD‘ from module dyna_td_agent implemented in class DynaTDAgent.
Dyna-TD uses temporal difference learning along with learning a model of the environment and doing planning in it.
Agent ‘Temporal Difference + Eligibility‘ from module td_lambda_agent implemented in class TDLambdaAgent.
An agent that uses temporal difference learning (e.g. Sarsa) with eligibility traces and function approximation (e.g. linear tile coding CMAC) to optimize its behavior in a given environment
Agent ‘Policy Replay‘ from module policy_replay_agent implemented in class PolicyReplayAgent.
Agent which loads a stored policy and follows it without improving it.
Agent ‘Random‘ from module random_agent implemented in class RandomAgent.
Agent ‘Actor Critic‘ from module actor_critic_agent implemented in class ActorCriticAgent.
This agent learns based on the actor critic architecture. It uses standard TD(lambda) to learn the value function of the critic. For this reason, it subclasses TDLambdaAgent. The main difference to TD(lambda) is the means for action selection. Instead of deriving an epsilon-greedy policy from its Q-function, it learns an explicit stochastic policy. To this end, it maintains preferences for each action in each state. These preferences are updated after each action execution according to the following rule:
Agent ‘RoundRobin‘ from module example_agent implemented in class ExampleAgent.
Agent ‘Direct Policy Search‘ from module dps_agent implemented in class DPS_Agent.
This agent uses a black-box optimization algorithm to optimize the parameters of a parametrized policy such that the accumulated (undiscounted) reward of the the policy is maximized.
Agent ‘Fitted-RMax‘ from module fitted_r_max_agent implemented in class FittedRMaxAgent.
Fitted R-Max is a model-based RL algorithm that uses the RMax heuristic for exploration control, uses a fitted function approximator (even though this can be configured differently), and uses Dynamic Programming (boosted by prioritized sweeping) for deriving a value function from the model. Fitted R-Max learns usually very sample-efficient (meaning that a good policy is learned with only a few interactions with the environment) but requires a huge amount of computational resources.

Agent base-class¶
Module for MMLF interface for agents
This module contains the AgentBase class that specifies the interface that all MMLF agents have to implement.
- class agents.agent_base.AgentBase(config, baseUserDir, *args, **kwargs)¶
MMLF interface for agents
Each agent that should be used in the MMLF needs to be derived from this class and implements the following methods:
Interface Methods
setStateSpace: : Informs the agent of the environment’s state space setActionSpace: : Informs the agent of the environment’s action space setState: : Informs the agent of the environment’s current state giveReward: : Provides a reward to the agent getAction: : Request the next action the agent want to execute nextEpisodeStarted: : Informs the agent that the current episode has terminated and a new one has started. - getAction()¶
Request the next action the agent want to execute
- getGreedyPolicy()¶
Returns the optimal, greedy policy the agent has found so far
- giveReward(reward)¶
Provides a reward to the agent
- nextEpisodeStarted()¶
Informs the agent that a new episode has started.
- setActionSpace(actionSpace)¶
Informs the agent about the action space of the environment
More information about action spaces can be found in State and Action Spaces
- setState(state, normalizeState=True)¶
Informs the agent of the environment’s current state.
If normalizeState is True, each state dimension is scaled to the value range(0,1). More information about (valid) states can be found in State and Action Spaces
- setStateSpace(stateSpace)¶
Informs the agent about the state space of the environment
More information about state spaces can be found in State and Action Spaces
- storePolicy(filePath, optimal=True)¶
Stores the agent’s policy in the given file by pickling it.
Pickles the agent’s policy and stores it in the file filePath. If the agent is based on value functions, a value function policy wrapper is used to obtain a policy object which is then stored.
If optimal==True, the agent stores the best policy it has found so far, if optimal==False, the agent stores its current (exploitation) policy.
Actor-critic¶
Agent that learns based on the actor-critic architecture.
This module contains an agent that learns based on the actor critic architecture. It uses standard TD(lambda) to learn the value function of the critic and updates the preferences of the actor based on the TD error.
- class agents.actor_critic_agent.ActorCriticAgent(*args, **kwargs)¶
Agent that learns based on the actor-critic architecture.
This agent learns based on the actor critic architecture. It uses standard TD(lambda) to learn the value function of the critic. For this reason, it subclasses TDLambdaAgent. The main difference to TD(lambda) is the means for action selection. Instead of deriving an epsilon-greedy policy from its Q-function, it learns an explicit stochastic policy. To this end, it maintains preferences for each action in each state. These preferences are updated after each action execution according to the following rule:
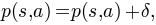
where delta is the TD error
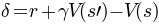
Action selection is based on a Gibbs softmax distribution:
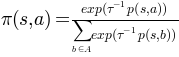
where tau is a temperature parameter.
Note that even though preferences are stored in a function approximator such that in principle, action preferences could be generalized over the state space, continuous state spaces are not yet supported.
New in version 0.9.9: Added Actor-Critic agent
- CONFIG DICT
gamma: : The discount factor for computing the return given the rewards lambda: : The eligibility trace decay rate tau: : Temperature parameter used in the Gibbs softmax distribution for action selection minTraceValue: : The minimum value of an entry in a trace that is considered to be relevant. If the eligibility falls below this value, it is set to 0 and the entry is thus no longer updated update_rule: : Whether the learning is on-policy or off-policy.. Can be either “SARSA” (on-policy) or “WatkinsQ” (off-policy) stateDimensionResolution: : The default “resolution” the agent uses for every state dimension. Can be either an int (same resolution for each dimension) or a dict mapping dimension name to its resolution. actionDimensionResolution: : Per default, the agent discretizes a continuous action space in this number of discrete actions. function_approximator: : The function approximator used for representing the Q value function preferences_approximator: The function approximator used for representing the action preferences (i.e. the policy)
Direct Policy Search (DPS)¶
Agent that performs direct search in the policy space to find a good policy
This agent uses a black-box optimization algorithm to optimize the parameters of a parametrized policy such that the accumulated (undiscounted) reward of the the policy is maximized.
- class agents.dps_agent.DPS_Agent(*args, **kwargs)¶
Agent that performs direct search in the policy space to find a good policy
This agent uses a black-box optimization algorithm to optimize the parameters of a parametrized policy such that the accumulated (undiscounted) reward of the the policy is maximized.
- CONFIG DICT
policy_search: : The method used for search of an optimal policy in the policy space. Defines policy parametrization and internally used black box optimization algorithm.
Dyna TD¶
The Dyna-TD agent module
This module contains the Dyna-TD agent class. It uses temporal difference learning along with learning a model of the environment and is based on the Dyna architecture.
- class agents.dyna_td_agent.DynaTDAgent(*args, **kwargs)¶
Agent that learns based on the DYNA architecture.
Dyna-TD uses temporal difference learning along with learning a model of the environment and doing planning in it.
- CONFIG DICT
gamma: : The discount factor for computing the return given the rewards epsilon: : Exploration rate. The probability that an action is chosen non-greedily, i.e. uniformly random among all available actions lambda: : The eligibility trace decay rate minTraceValue: : The minimum value of an entry in a trace that is considered to be relevant. If the eligibility falls below this value, it is set to 0 and the entry is thus no longer updated update_rule: : Whether the learning is on-policy or off-policy.. Can be either “SARSA” (on-policy) or “WatkinsQ” (off-policy) stateDimensionResolution: : The default “resolution” the agent uses for every state dimension. Can be either an int (same resolution for each dimension) or a dict mapping dimension name to its resolution. actionDimensionResolution: : Per default, the agent discretizes a continuous action space in this number of discrete actions planner: : The algorithm used for planning, i.e. for optimizing the policy based on a learned model model: : The algorithm used for learning a model of the environment function_approximator: : The function approximator used for representing the Q value function
Fitted R-Max¶
Fitted R-Max agent
Fitted R-Max is a model-based RL algorithm that uses the RMax heuristic for exploration control, uses a fitted function approximator (even though this can be configured differently), and uses Dynamic Programming (boosted by prioritized sweeping) for deriving a value function from the model. Fitted R-Max learns usually very sample-efficient (meaning that a good policy is learned with only a few interactions with the environment) but requires a huge amount of computational resources.
- class agents.fitted_r_max_agent.FittedRMaxAgent(*args, **kwargs)¶
Fitted R-Max agent
Fitted R-Max is a model-based RL algorithm that uses the RMax heuristic for exploration control, uses a fitted function approximator (even though this can be configured differently), and uses Dynamic Programming (boosted by prioritized sweeping) for deriving a value function from the model. Fitted R-Max learns usually very sample-efficient (meaning that a good policy is learned with only a few interactions with the environment) but requires a huge amount of computational resources.
See also
Nicholas K. Jong and Peter Stone, “Model-based function approximation in reinforcement learning”, in “Proceedings of the 6th International Joint Conference on Autonomous Agents and Multiagent Systems” Honolulu, Hawaii: ACM, 2007, 1-8, http://portal.acm.org/citation.cfm?id=1329125.1329242.
- CONFIG DICT
gamma: : The discount factor for computing the return given the rewards# min_exploration_value: : The agent explores in a state until the given exploration value (approx. number of exploratory actions in proximity of state action pair) is reached for all actions RMax: : An upper bound on the achievable return an agent can obtain in a single episode planner: : The algorithm used for planning, i.e. for optimizing the policy based on a learned model model: : The algorithm used for learning a model of the environment function_approximator: : The function approximator used for representing the Q value function actionDimensionResolution: : Per default, the agent discretizes a continuous action space in this number of discrete actions
Model-based Direct Policy Search (MBDPS)¶
The Model-based Direct Policy Search agent
This module contains an agent that uses the state-action-reward-successor_state transitions to learn a model of the environment. It performs than direct policy search (similar to the direct policy search agent using a black-box optimization algorithm to optimize the parameters of a parameterized policy) in the model in order to optimize a criterion defined by a fitness function. This fitness function can be e.g. the estimated accumulated reward obtained by this policy in the model environment. In order to enforce exploration, the model is wrapped for an RMax-like behavior so that it returns the reward RMax for all states that have not been sufficiently explored.
- class agents.mbdps_agent.MBDPS_Agent(*args, **kwargs)¶
The Model-based Direct Policy Search agent
An agent that uses the state-action-reward-successor_state transitions to learn a model of the environment. It performs direct policy search (similar to the direct policy search agent using a black-box optimization algorithm to optimize the parameters of a parameterized policy) in the model in order to optimize a criterion defined by a fitness function. This fitness function can be e.g. the estimated accumulated reward obtained by this policy in the model environment. In order to enforce exploration, the model is wrapped for an RMax-like behavior so that it returns the reward RMax for all states that have not been sufficiently explored. RMax should be an upper bound to the actual achievable return in order to enforce optimism in the face of uncertainty.
- CONFIG DICT
gamma: : The discount factor for computing the return given the rewards planning_episodes: : The number internally simulated episodes that are performed in one planning step policy_search: : The method used for search of an optimal policy in the policy space. Defines policy parametrization and internally used black box optimization algorithm. model: : The algorithm used for learning a model of the environment
Monte-Carlo¶
Monte-Carlo learning agent
This module defines an agent which uses Monte Carlo policy evaluation to optimize its behavior in a given environment
- class agents.monte_carlo_agent.MonteCarloAgent(*args, **kwargs)¶
Agent that learns based on monte-carlo samples of the Q-function
An agent which uses Monte Carlo policy evaluation to optimize its behavior in a given environment.
- CONFIG DICT
gamma: : The discount factor for computing the return given the rewards epsilon: : Exploration rate. The probability that an action is chosen non-greedily, i.e. uniformly random among all available actions visit: : Whether first (“first”) or every visit (“every”) is used in Monte-Carlo updates defaultQ: : The initially assumed Q-value for each state-action pair. Allows to control initial exploration due to optimistic initialization
Option¶
Random¶
MMLF agent that acts randomly
This module defines a simple agent that can interact with an environment. It chooses all available actions with the same probability.
This module deals also as an example of how to implement an MMLF agent.
- class agents.random_agent.RandomAgent(*args, **kwargs)¶
Agent that chooses uniformly randomly among the available actions.
Temporal Difference Learning¶
TD(0)¶
Agent based on temporal difference learning
This module defines a base agent for all kind of agents based on temporal difference learning. Most of these agents can reuse most methods of this agents and have to modify only small parts.
Note: The TDAgent cannot be instantiated by itself, it is a abstract base class!
- class agents.td_agent.TDAgent(*args, **kwargs)¶
A base agent for all kind of agents based on temporal difference learning. Most of these agents can reuse most methods of this agents and have to modify only small parts
Note: The TDAgent cannot be instantiated by itself, it is a abstract base class!
TD(lambda) - Eligibility Traces¶
Agent based on temporal difference learning with eligibility traces
This module defines an agent that uses temporal difference learning (e.g. Sarsa) with eligibility traces and function approximation (e.g. linear tile coding CMAC) to optimize its behavior in a given environment
- class agents.td_lambda_agent.TDLambdaAgent(*args, **kwargs)¶
Agent that implements TD(lambda) RL
An agent that uses temporal difference learning (e.g. Sarsa) with eligibility traces and function approximation (e.g. linear tile coding CMAC) to optimize its behavior in a given environment
- CONFIG DICT
update_rule: : Whether the learning is on-policy or off-policy.. Can be either “SARSA” (on-policy) or “WatkinsQ” (off-policy) gamma: : The discount factor for computing the return given the rewards epsilon: : Exploration rate. The probability that an action is chosen non-greedily, i.e. uniformly random among all available actions epsilonDecay: : Decay factor for the exploration rate. The exploration rate is multiplied with this value after each episode. lambda: : The eligibility trace decay rate minTraceValue: : The minimum value of an entry in a trace that is considered to be relevant. If the eligibility falls below this value, it is set to 0 and the entry is thus no longer updated replacingTraces: : Whether replacing or accumulating traces are used. stateDimensionResolution: : The default “resolution” the agent uses for every state dimension. Can be either an int (same resolution for each dimension) or a dict mapping dimension name to its resolution. actionDimensionResolution: : Per default, the agent discretizes a continuous action space in this number of discrete actions function_approximator: : The function approximator used for representing the Q value function